本站4月20日消息,GitHub的Lvmin Zhang聯合斯坦福大學的Maneesh Agrawala,發布了一項突破性的新技術FramePack,通過在視頻擴散模型中使用固定長度的時域上下文,可以更高效地生成時間更長、質量更高的視頻。
根據實測,基于FramePack構建的130億參數模型,只需一塊6GB顯存的顯卡,就能生成60秒鐘的視頻。
FramePack是一種神經網絡架構,使用多級優化策略,完成本地AI視頻生成。
目前,它底層基于定制版的騰訊混元模型,不過現有的預訓練模型,都可以通過FramePack進行微調、適配。

典型的視頻擴散模型在生成視頻時,需要首先處理此前生成的帶有噪音的幀,然后預測下一個噪音更少的幀,而每生成一幀所需要輸入的幀數量,就是時域上下文長度,會隨著視頻的體積而增加。
這就對顯存有著很高的要求,一般至少得有12GB,而如果顯存不夠多,生成的視頻就會很短,質量很差,生成的時間也會很長。
FramePack會根據輸入幀的重要性,對所有輸入幀進行壓縮,改變為固定的上下文長度,顯著降低對顯存的需求,而且計算消耗與圖片擴散模型類似。
同時,每一幀畫面生成之后,都會實時顯示,方便即時預覽。
FramePack還可以緩解“漂移”(drifting)現象,也就是視頻長度增加、質量下降的問題,從而在不顯著犧牲質量的同時,生成更長的視頻。
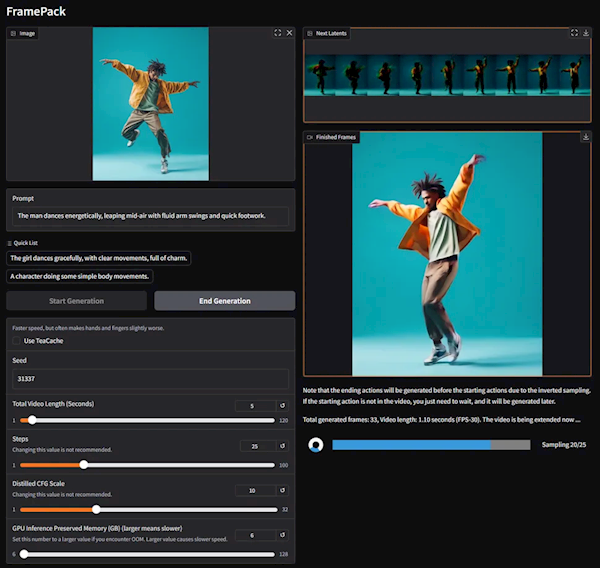
FramePack數據格式支持FP16、BF16,顯卡硬件支持RTX 50、RTX 40、RTX 30系列顯卡,除了RTX 3050 4GB幾乎所有的近代顯卡都沒問題。
在RTX 20系列和更老顯卡上尚未經過驗證,也沒有提及AMD、Intel處理器的需求。
操作系統支持Windows、Linux。
性能方面,RTX 4090經過teacache優化之后,每秒可以生成大約0.6幀。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。



